
 How do you look up a word in a Chinese or Japanese dictionary?
How do you look up a word in a Chinese or Japanese dictionary?
[--markrose]
The vast majority of Chinese characters can be divided into two parts, the radical and the phonetic. Each part is another, simpler character. The radical gives an idea of the meaning-- rather a vague idea, since traditionally there were only 214 different radicals. The phonetic identifies the sound, with a bit more precision: generally, all the characters that share a phonetic rhymed 2000 years ago in Archaic Chinese.
The radical (shown in the above characters in red) is used only for its meaning; its pronunciation is irrelevant. The phonetic (shown in blue) is used only for its sound; its meaning is irrelevant. Note that a single character, such as nü3 'woman' or kôu 'mouth' above, can be a radical in one character and a phonetic in another. The case of gu 'aunt', itself built out of radical + phonetic, but used for its own phonetic value in gu 'type of mushroom', is also fairly common.
Characters are arranged in most Chinese dictionaries by radical. To find an unknown character, then, you identify the radical, and look up its section in the dictionary. The radicals are arranged in order of increasing complexity. Each radical's section is ordered by the number of strokes in the character. Several characters may have the same number of strokes; these must simply be scanned till the right one is found.
Sometimes it isn't easy to identify the radical-- it's in an odd position (e.g. on the bottom or the right rather than the top or left side-- cf. rú 'like' above); or it's drawn in an abbreviated form; or it's not clear which of several similar radicals the character is listed under. It's also important to know the proper method for counting strokes (e.g. nü3 'woman', kôu 'mouth', and ma 'horse' all count as three strokes).
If a character isn't composed of a radical + phonetic, it's usually treated as one, graphically, for the purposes of dictionary lookup. For instance, the character for hâo 'good' is composed of the characters for 'woman' and 'child'-- a semantic compound. It's simply listed under the nü3 'woman' radical, although zî 'child' is not a phonetic.
The People's Republic simplified a number of characters and radicals, and this changed the number of radicals-- there's 224 in my dictionary, for instance. The Japanese have made their own separate simplification.
What about Nostratic and Proto-World?
[--markrose]
In recent years some some linguists have attempted to reconstruct languages far older than Indo-European.
Nostratic, said to underlie the Indo-European, Kartvelian (South Caucasian), Afro-Asiatic, Dravidian, Uralic, Altaic, Chukchi-Kamchatkan, and Eskimo-Aleut families, was first proposed by Holger Pedersen in 1903. More recently the greater part of work on Nostratic has been done by Soviet linguists led by Vladislav Illich-Svitych, Aaron Dolgopolsky, and Vitaly Shevoroshkin.
The methodology is the traditional comparative method, and over 600 roots have been proposed. Most linguists remain skeptical, believing that chance processes will have obscured any relationship at this level beyond reconstruction, or question the accuracy of the derivations (a charge which makes Nostraticists bristle). Others simply suspend judgment, especially since much of the supporting material for Nostratic is available only in Russian.
A good overview on Nostratic is Kaiser and Shevoroshkin, "Nostratic", in the Annual Review of Anthropology, 17:309. Illich-Svitych's original Russian article (from Etymologia, 1965) has been translated in Shevoroshkin, ed., Reconstructing Languages and Cultures (1989).
Joseph Greenberg has proposed a grouping which covers much the same language areas (omitting Afro-Asiastic and Dravidian, but adding Ainu and Gilyak), called Eurasiatic. Greenberg's method of mass comparison (which he has also used to group together almost all Native American languages into one superfamily, Amerind) basically consists of assembling huge lists of common words and doing eyeball comparisons.
This methodology has been severely criticized by many historical linguists. If 'mass comparison' were applied to the Indo-European languages, it would be bedevilled by false positives (caused by borrowing or chance) and by specious phonetic or semantic similarites. Greenberg's methods seem to linguists to abandon the very methodological severity which has put Indo-European linguistics on a scientific footing, and distinguished it from the work of cranks. Relax the rules enough, and you can derive any language from any other.
Greenberg replies that the patterns he has found are compelling enough to justify his methods, and that he is merely following in the footsteps of the originators of the comparative method: linguists had to decide that the Indo-European languages were related before attempting reconstructions.
The ultimate areal comparison would be Proto-World, the hypothetical ancestor of all human languages. Greenberg has mentioned Proto-World, but since he is not much interested in reconstruction, his proposal is not much more than a statement of the monogenetic theory (a single origin for all languages). Most linguists are skeptical that anything could be reconstructed at this hypothetical time depth.
Greenberg's work on Amerind can be found in Language in the Americas (1987); on Eurasiatic, in the forthcoming Indo-European and Its Closest Relatives: The Eurasiatic Language Family. Introductions to the Nostratic and Proto-World controversies were published in both The Atlantic and Scientific American in April 1991. The essays in Lamb and Mitchell, eds., Sprung From Some Common Source (1991), are also relevant.
Loren Petrich maintains an annotated bibliography on Indo-European, Nostratic, and Proto-World. I am also indebted to Peter Michalove for citations used in this entry.
What are phonemes and why's it so hard to lose a foreign accent?
[--markrose]
The sounds (phones) humans can make are infinite; there's (almost always) a continuum of phones between any two phones.
In any one language, however, phones are grouped into 20 to 60 or so discrete groups of sounds called phonemes. The range of variation for each phoneme is discounted by speakers and hearers of the language, who perceive the entire range as "the same sound."
The diversity of phones, and their grouping into phonemes, can be clearly seen on this chart from William Labov's Principles of Linguistic Change (1994). The chart is a graph of formant frequencies F1 against F2 for the main vowels of fifty words as spoken by a single person-- in effect, a plot of fifty actual phones. (The words on the chart-- beat, bait, etc.-- are not the words being spoken, but just examples of words with those vowel sounds.)
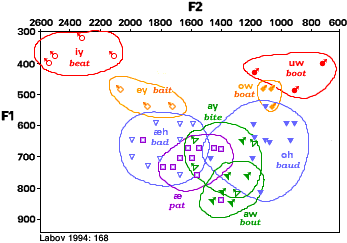
(Most of the sounds plotted are diphthongs, which are glides between two sounds; this accounts for some of the overlaps on the diagram (and for the little arrows on the symbols). For instance, the sounds Labov calls ay and aw start in about the same place, but ay heads 'northwest' toward [i] and aw heads 'northeast' toward [u].)
The English phoneme /p/ has two phonetic realizations or allophones: aspirated [ph] beginning a word and non-aspirated [p] elsewhere. But since the two types of /p/ never distinguish one word from another, speakers of English generally don't even perceive the difference. (Linguists write phonemic transcriptions between /slashes/, and phonetic transcriptions in [brackets].)
If we can find two words with different meaning but only one difference in sound between them-- a minimal pair-- then we've found distinct phonemes; e.g. /p/ and /b/ in English 'pit' and 'bit'. If two sounds never occur in the same phonetic environment (e.g. English [p] and [ph])-- if they're in complementary distribution-- then they're probably allophones of a single phoneme.
Other languages do not divide up the phonetic space in the same way. For instance, /p/ and /ph/ are separate phonemes in Mandarin Chinese (as in /pa1/ 'eight' and /pha1/ 'flower'). And the vowels of late and let, phonemes in English, are allophones of a single phoneme /e/ in Spanish.
We're trained from childhood to make the phonetic distinctions our language uses to keep its phonemes apart, and to ignore those that lie within phonemes. Learning to make different distinctions in a foreign language is quite difficult-- usually harder than making new sounds our native language lacks entirely. We'll continue to have an accent in the new language so long as we hear its sounds through our native language's phonemic filter.
How likely are chance resemblances between languages?
[--markrose]
It depends-- to an astonishing degree-- on the amount of phonetic and semantic leeway you allow for a match. But in general the answer is "Quite likely."
For the sort of comparisons that are often posted to sci.lang, where perhaps just two consonants match, or nearly match, and the semantic matchups are quirky, one can expect literally hundreds of random matches.
How are tone languages sung?
[--markrose] It varies. Tones are basically ignored in Mandarin Chinese songs, for instance. (Does this make them hard to understand? Often, yes.) However, Cantonese songs are generally written in such a way as to preserve the relative pitch of successive syllables. E.g. a low tone following a high tone will be on a lower note. For more, see Marjorie Chan's paper on Tone and Melody in Cantonese.
Why are there so many words for Germany?
Basically, because there were Germans before there was a Germany. Each of the Germans' neighbors came up with their own name for them, long before there was a German state that people might want to refer to uniformly.
German is a relatively recent borrowing from Latin Germanus, whose origins are uncertain. It's been referred to Latin germanus 'brotherly', Germanic *geromann- 'spear-man', Old Irish gair 'neighbour', etc.
Deutsch comes from Proto-Germanic *theudisko-z 'of the people', from *theudâ 'people, nation'; originally it was used to distinguish the speech of the people from Latin, the language of scholarship. The English word 'Dutch' is a derivative, and used to be used for any northern Germanic people, later narrowed down to those closest to England; the older usage is preserved in 'Pennsylvania Dutch'.
The word *theudâ survived into Middle English as thede, but was supplanted by Romance borrowings such as 'people' and 'nation'. Non-Germanic cognates include Oscan touto, Irish tu:ath, and Lithuanian tauta, all meaning 'people'.
Italian tedesco is another derivative of *theudisko-z.
Teutonic derives from a name of an ancient tribe in Jutland, the Teutones; if these were a German tribe their name is presumably another derivative of *theudâ.
French allemand (and Spanish alemán, etc., as well as older English Almain) derive from a particular tribe of Germans, the Alemanni ('all the men').
Finnish saksa derives from the name of another tribe, the Saxons.
Russian nemets is related to nemoj 'dumb, mute'; to the ancient Slavs, not speaking in an understandable language was as good as not speaking at all. Hungarian német is borrowed from Slavic.
Latvian Va:cija may derive from a word meaning 'west'.
Why do both English and French have plurals in -s?
[--Miguel Carrasquer Vidal (adapted by markrose)]
Despite what one might think, these are independent developments.
The English s-plural comes from the PIE o-stem nominative plural ending *-o:s, apparently extended in Germanic to *-o:s-es by addition of the PIE plural suffix *-es (*-o:s itself comes from *-o-es). This *-o:ses became Proto-Germanic *-o:ziz or *-o:siz, depending on the accent, which gave the attested forms-- Gothic -o:s, Old English -as, Old Saxon -os, and Old Norse -ar (with the change *z --> r). Already in Old English there was a tendency to extend this plural in -s to words that were not a-stems, a tendency which has since become nearly universal.
The n-plural of German is generalized from the PIE n-stems (*-on-es --> -en). It was still present in Old English n-stems, and survives today in a few words like 'oxen'.
The Romance s-plurals (-as, -os, -es) are derived from the accusative (PIE *-a:ns, *-ons, *-ens). Old French still had separate nominative and oblique (accusative/ablative) forms, but in the end, grammatical cases were dropped completely, and usually only the oblique forms were retained.
In Italian and Romanian, final -s was phonetically lost, and the plurals are based on the nominative. The Latin nominative plural, at least in the o- and a:-stems, was based on PIE *-i, of pronominal origin, not *-es as in most other IE languages.
How did genders and cases develop in IE?
[--Mikael Thompson]
Early stages of proto-Indo-European (PIE) didn't have feminine gender. This is attested in Hittite, the oldest recorded IE language; it had only masculine and neuter genders, divided basically between animate and inanimate objects. For most noun classes the PIE endings can be reconstructed as follows:
Animate Inanimate Subject *-s *-0 Object *-m *-0
For animate nouns, *-s indicated the source of action, *-m the thing acted upon; the zero ending indicates no syntactic role. The basic idea is that only living things can act upon other things, so only animate nouns could take the *-s.
Such a system is characteristic of active/stative languages. Other features of PIE fit in with this observation; for instance, in PIE objects like fire and water which are inanimate but move seemingly of their own will have two separate names. In many languages with an active-stative distinction there are such pairs of words. As this distinction was lost in IE, different branches retained just one of the words: e.g. English water, Greek hydor, Hittite watar form one group (from PIE *wed-), while Latin aqua is from PIE *akwa:-.
The animate nouns are the historical source for the masculine gender, and the inanimate nouns for the neuter. This is why in all the classic IE languages the neuter nominative and accusative have identical forms, and the only basic difference between masculine and neuter nouns is in the accusative.
Earlier historical linguists cheerfully reconstructed eight cases for PIE, on the model of Sanskrit; but the IE languages with many cases are now considered to be innovative, not conservative. The other cases developed from postpositions or derivational suffixes. Luwian, a sister language of Hittite, for instance, has no genitive, but has an adjective-forming suffix -assi, as in harmah-assi-s 'of the head'. (This is an adjective, not a genitive, because it can be declined.) Genitives in other languages often seem to be developments of cognates to this suffix.
PIE didn't bother much with specifying plurals, but when it did, it added an *-s or other endings. The neuter plural in all IE languages is not descended from this, however-- active/stative languages typically don't mark plurals for inanimate nouns-- but is instead a collective noun, treated grammatically as a singular. This collective noun ended in *-a in the nominative and accusative, and eventually it developed into the feminine, which in all the old IE languages has the same form in the nominative singular as does the neuter plural nominative- accusative. It is also why the Greek neuter plural took a singular verb.
The reason it is called the feminine, of course, is that nouns indicating females fell in this gender most of the time. This is puzzling, and probably we must accept it as a fact whose explanation can't be recovered from the depths of time.
What is the Sapir-Whorf hypothesis?
[--markrose]
According to the Sapir-Whorf hypothesis, language determines the categories and much of the content of thought. "We dissect nature along lines laid down by our native languages... We cannot talk at all except by subscribing to the organization and classification of data which the [speech community] decrees," said Whorf, in Language, Thought, and Reality (1956). "The fact of the matter is that the 'real world' is to a large extent unconsciously built up on the language habits of the group," said Sapir.
Both were students of Amerindian languages, and were drawn to this conclusion by analysis of the grammatical categories and semantic distinctions found in these languages, fascinatingly different from those found in European ones. (Neither linguist used the term 'Sapir-Whorf hypothesis', however; Whorf referred to the 'linguistic relativity principle'. Moreover, the principle was almost entirely elaborated by Whorf alone.)
The idea enjoyed a certain vogue midcentury, not only among linguists but among anthropologists, psychologists, and science fiction writers.
However, the strong form of the hypothesis is not now widely believed. The conceptual systems of one language, after all, can be explained and understood by speakers of another. And grammatical categories do not really explain cultural systems very well. Indo-European languages make gender a grammatical category, and their speakers may be sexist-- but speakers of Turkish or Chinese, languages without grammatical gender, are not notably less sexist.
Whorf's analysis of what he called "Standard Average European" languages is also questionable. E.g. he claims that "the three-tense system of SAE verbs colors all our thinking about time." Only English doesn't have three tenses; it has two, past and present; future events are expressed by the present ("I see him tomorrow"), or by a modal expression, merely one of a large class of such synthetic expressions. And for that matter, English distinguishes more like six than three times ("I had gone, I went, I just arrived, I'm going, I'm about to go, I'll go").
To prove his point, Whorf collected stories of confusions brought about by language. For instance, a man threw a spent match into what looked like a pool of water; only there was decomposing waste in the water, and escaping gas was ignited by the spark-- boom! But it's not clear that any linguistic act is involved here. The man could think the pool looked like water without thinking of the word 'water'; and he could fail to notice the flammable vapors without doing any thinking at all.
A weak form of the Sapir-Whorf hypothesis-- that language influences without determining our categories of thought-- still seems reasonable, and is even backed up by some psychological experiments-- e.g. Kay & Kempton's finding that, in distinguishing color triads, a pair distinguished by color names can seem more distinct than a pair with the 'same' name which are actually more divergent optically (American Anthropologist, March 1984).
It should be emphasized that, in their willingness to consider the idea that non-Western people have languages and worldviews that match the European's in precision and elegance, Sapir and Whorf were far ahead of their time.